Study Groups Pt. 2
This post is intended to be a continuation of the previous post discussing study groups. You can probably find that post pretty easily on this site. If you haven't seen it, go back and read it!
I would also like to say that I am quite interested in criticism of this little article. I don't intend to go much farther with this project, but discussion about it could be quite interesting. And of course if you find errors, let me know!
Simulation
I've expanded the model a bit for this one. Here is what happens:
- People enter a room one at a time
- People will chose the study group with best fitness and join it
- On occasion, an individual will decide to be selfless, meaning, the
individual will not join a group if their joining will hurt the
fitness of the group
- if an individual attempts to be selfless, but there are no groups they can join without hurting them, they will have to join normally
- After a member has joined, for every group, if the group's size is
greater than the optimal group size, there is some chance the group
will split
- if the group splits, half of the groups members stay in the group and the other half all join groups one at a time (goto 1 essentially for every member that has left the group)
Just to recap, fitness is determined based on group size, using this differential equation:
\[ \frac{dF}{dn} = \alpha - \beta n \]
where $ α $ is an individual member's contribution (every member is assumed to have the same contribution) and $ β $ is the amount the member will detract from the group (also assumed the same for all members).
The chance an individual will be selfless is some percentage, also assumed constant for all members.
And finally, the chance come group will split, given that it has exceeded the optimal size, is another percentage.
One more detail, in the simulation, I have set a fixed number of available groups. All groups start with 0 members. As long as the number of available groups is substantially larger than the number of people to join the groups, this fact doesn't seem to have an effect on the results. However, if we do something like try and cram 16 people into 10 groups, that can get kind of interesting.
Because there is some element of randomness, I will run many trials of the simulation to get results.
Criticism of the model
There are a couple obvious problems with this model.
- Realistically, people do not all contribute equally to a group, this
is a pretty dramatic simplification. Same for member detriment and
selflessness.
- However, I did a small test to see how much of an impact this has and I (weakly) concluded that for large $ n $ this effect goes away. Unfortunatley, I'm not really testing with large $ n $, so we will have to take this fact into consideration in our interpretation of the results.
- The selflessness idea is fairly unrealistic. In reality an individual can't determine if their joining will damage the fitness of the group, because they have no concrete way to compute the group's fitness. However, because this is done by chance, if we keep the chance low we can approximate the effect of this optimal size uncertainty. To explain what I mean, consider this. Assume an individual can only estimate whether or not they will hurt a group, and lets say they are only right 50 percent of the time. Then, lets say that this person has a 50 percent chance of being selfless. So essentially, given a group above optimal size, there is a 25 percent chance the person won't join it. We can consider this when setting the selflessness parameter.
- The way groups split is fairly unrealistic. Groups, like individuals, can't say for sure if they are above optimal size. However, using the same argument as the previous, I think we can get away with this.
So, the biggest flaw we will have to overcome is (1), but, the specific kind of experiment I plan to run lessens the impact of this problem.
The Experiment
I intend to try and figure out if group splitting or individual selflessness will do a better job at keeping groups close to optimal size (or at least not create tons of 1 person groups or tons of very large groups).
So, for some values of $ α $, and $ β $, I varied both the selflessness chance and the group split chance from 0.0 to 0.95, in 5 percent increments. So every pair is tested.
I've created some plots to demonstrate my results. I'm also kind of lazy, so I didn't label them, but, I'll give you a badly labeled example here just to be nice.
This particular image is shows the percentage of groups at optimal size for various values of selflessness and group split chance.
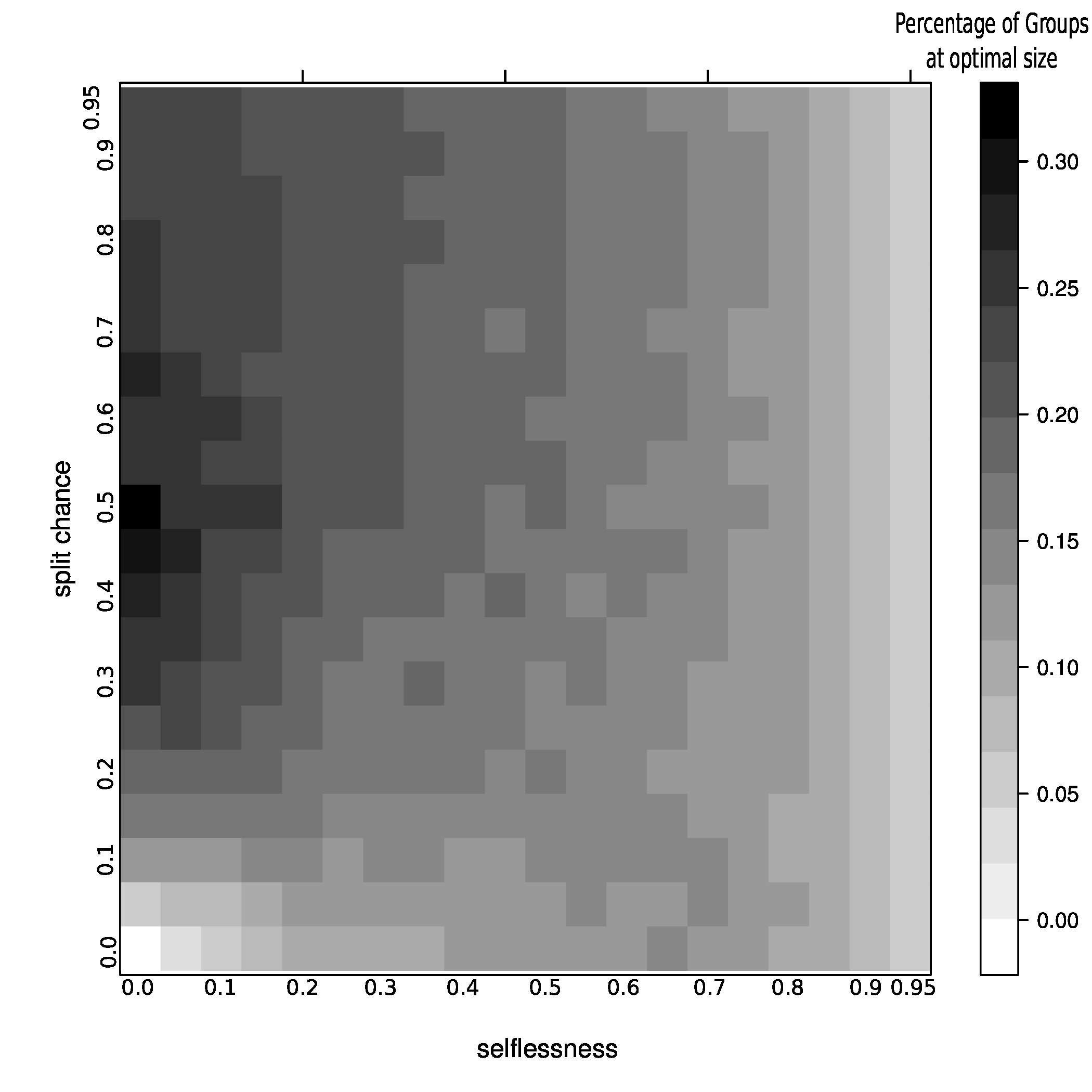
All of the images from here on out are essentially the same, although they grayness may have a different meaning, I'll be careful to explain what you are looking at in the file names and in this document, but I'm not going to go back all the images, sorry!
Results
First test we are going to look at.
member_contrib=1.000000 member_detriment=0.500000 num_joiners=5 max_groups=50 trials=1000
Here are the images for all the results:
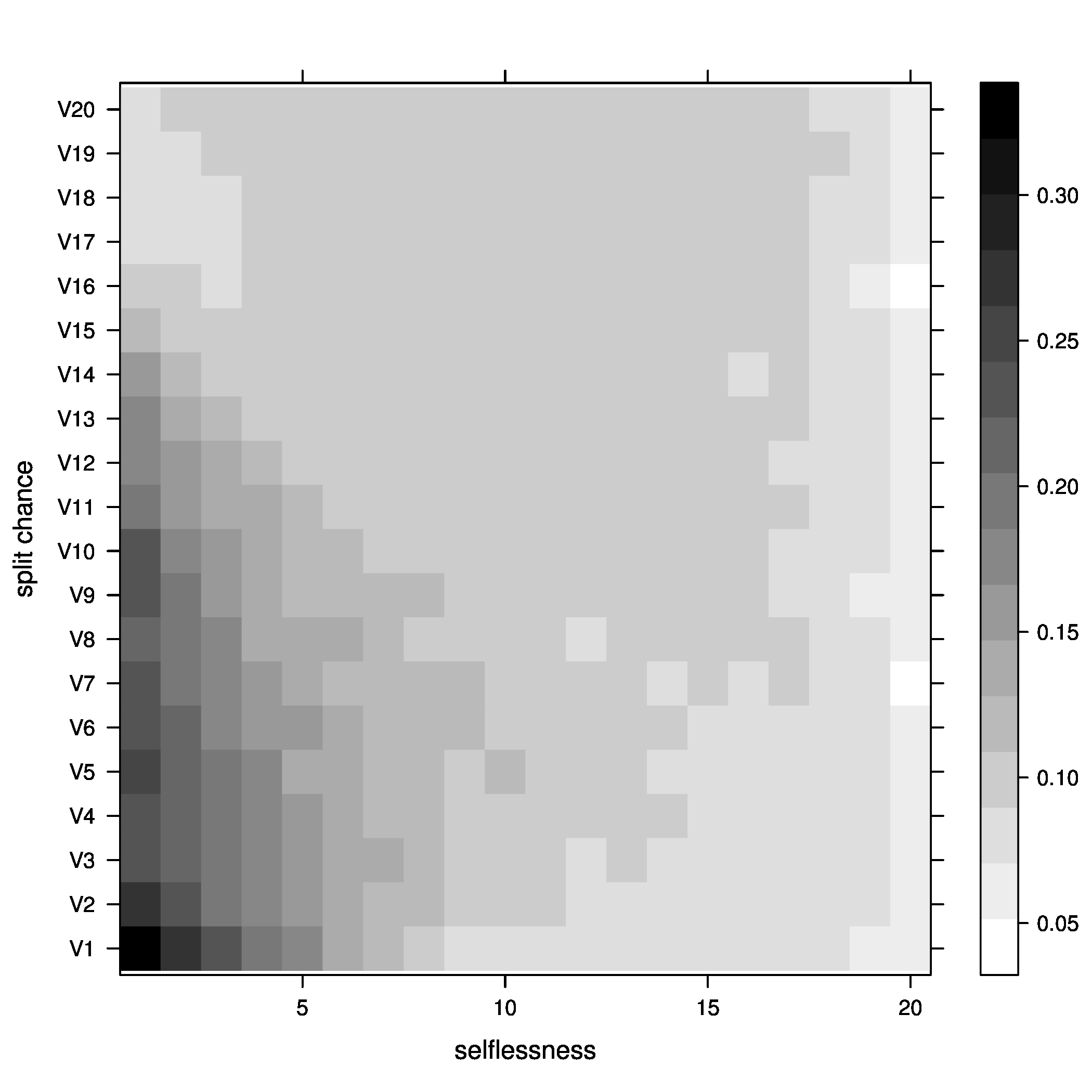
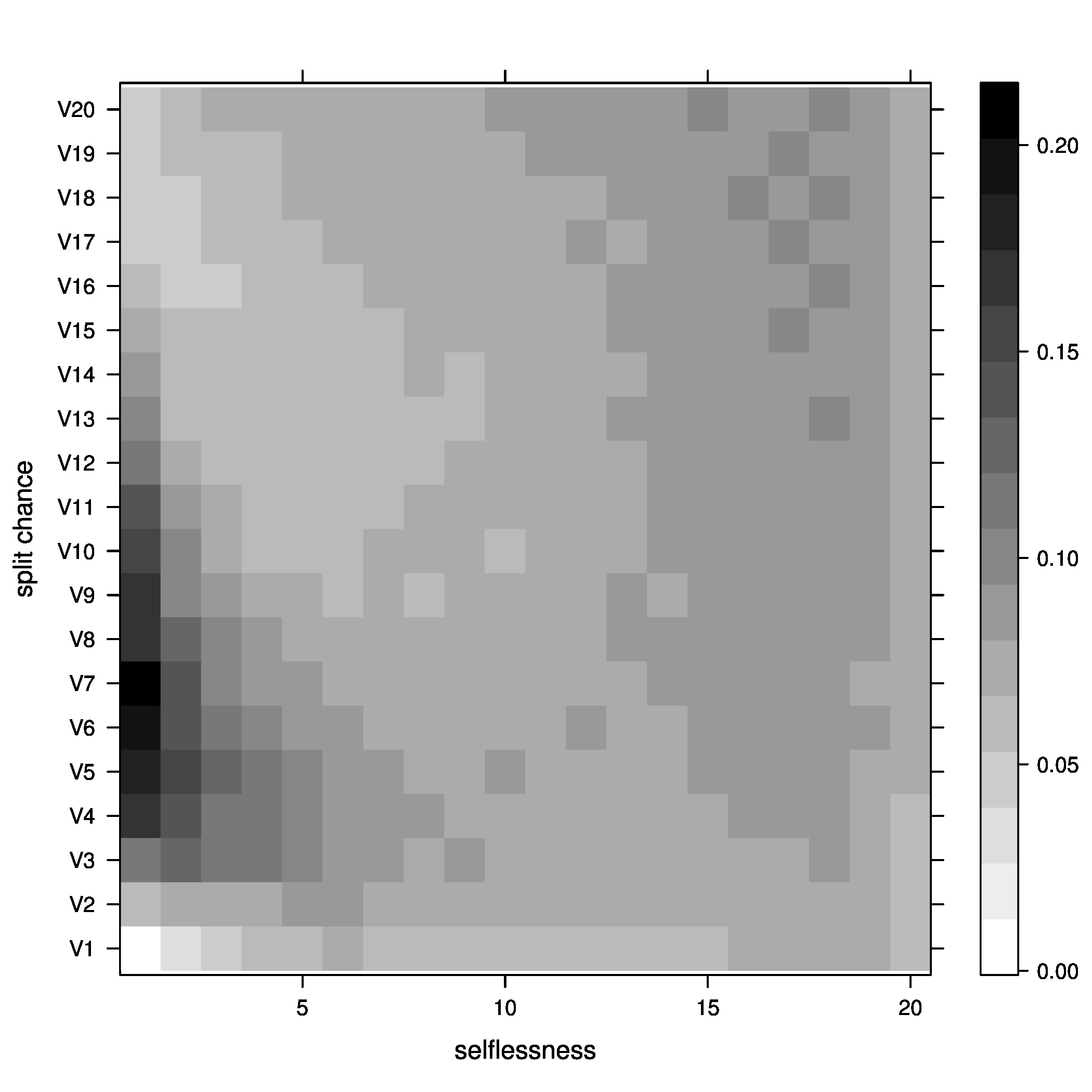
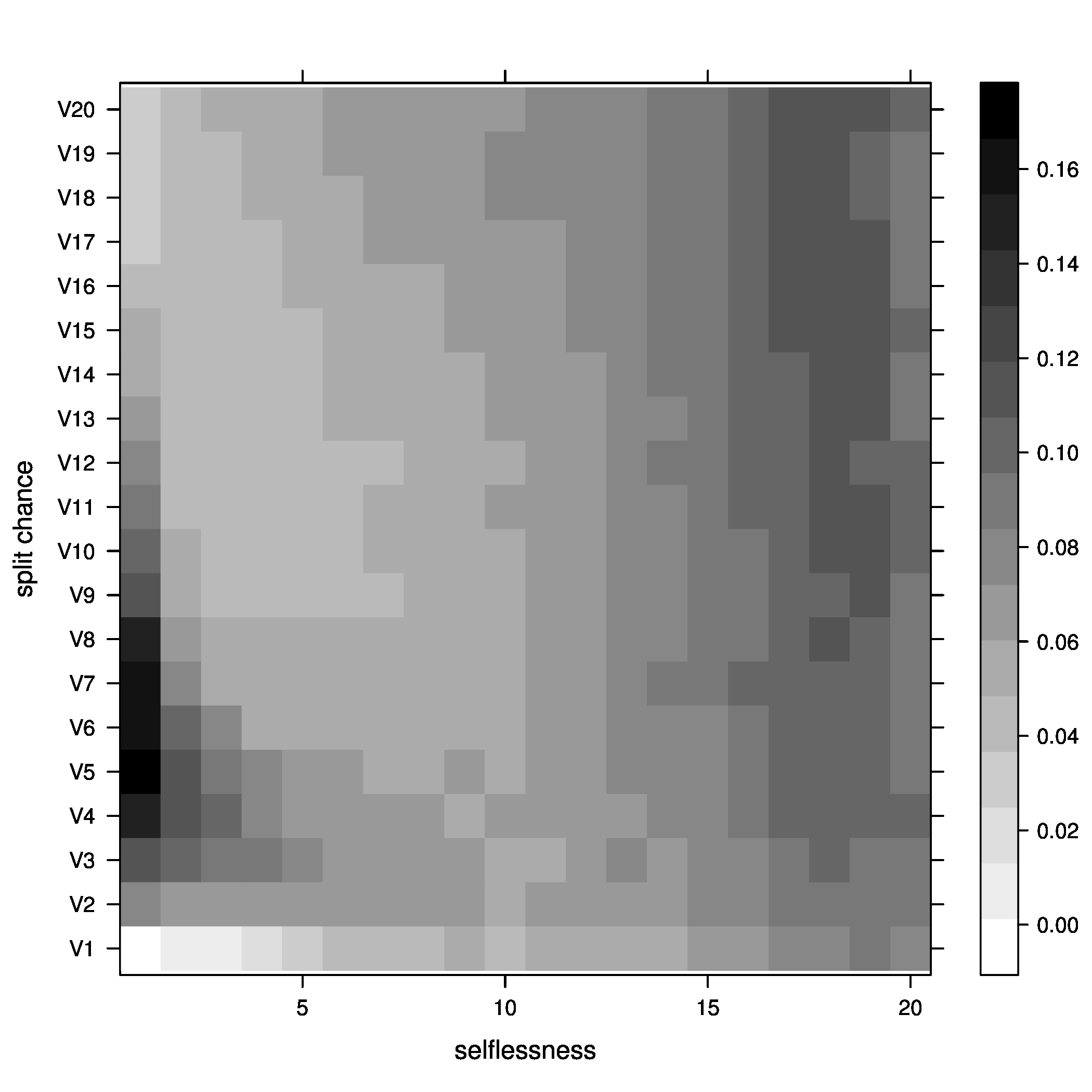
- Percentage of groups at optimal size
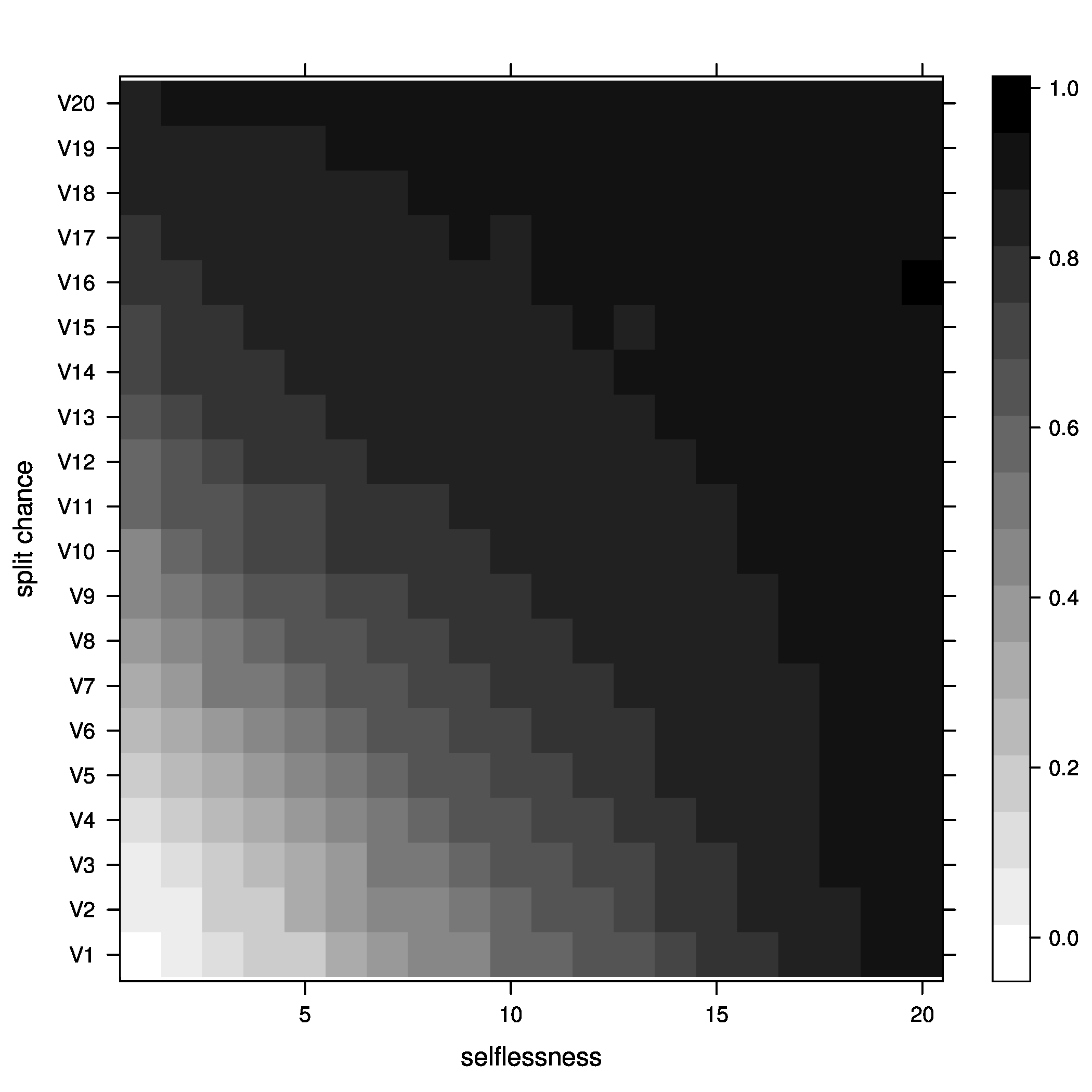
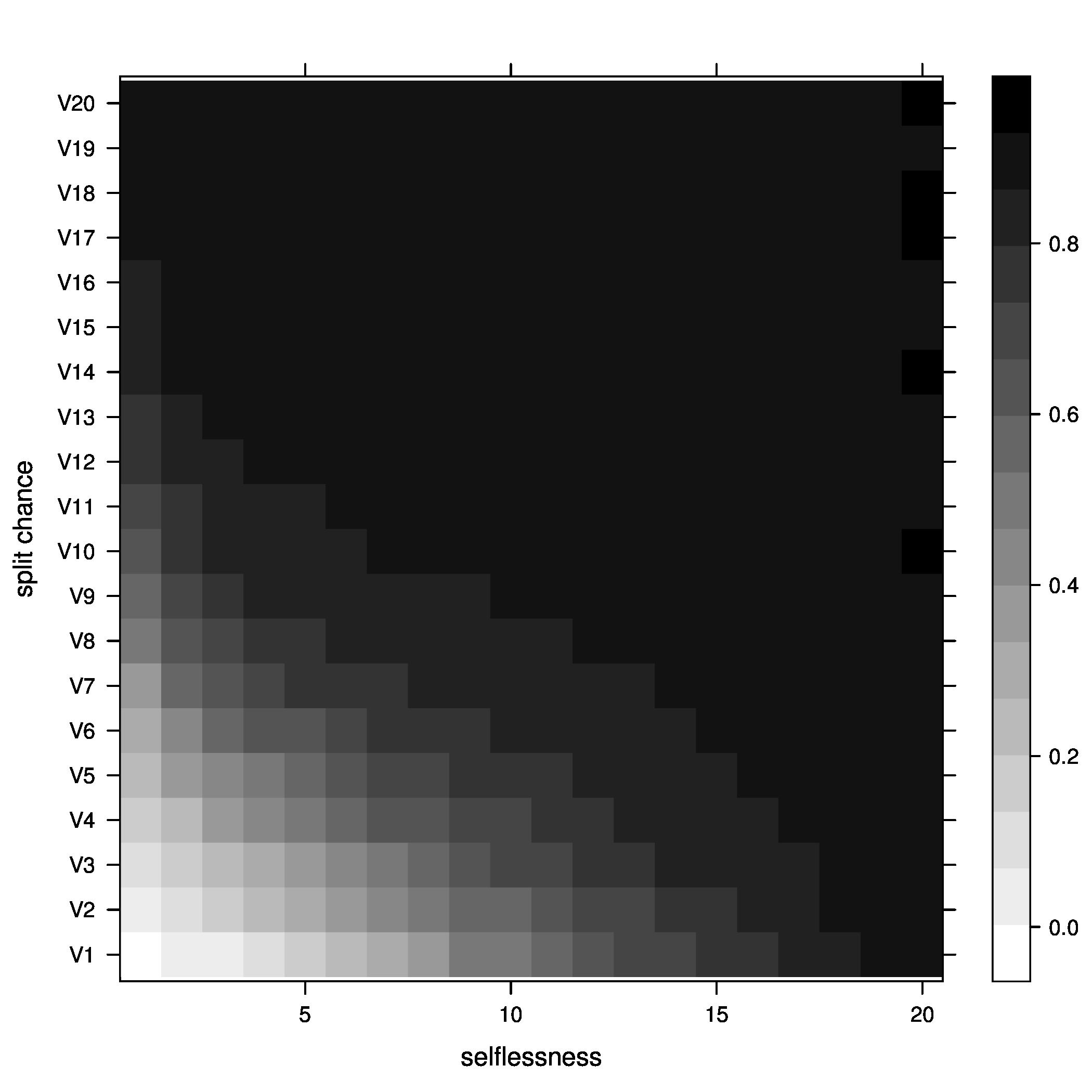
Figure 2: joiners=5, at optimal - Percentage of groups above optimal size
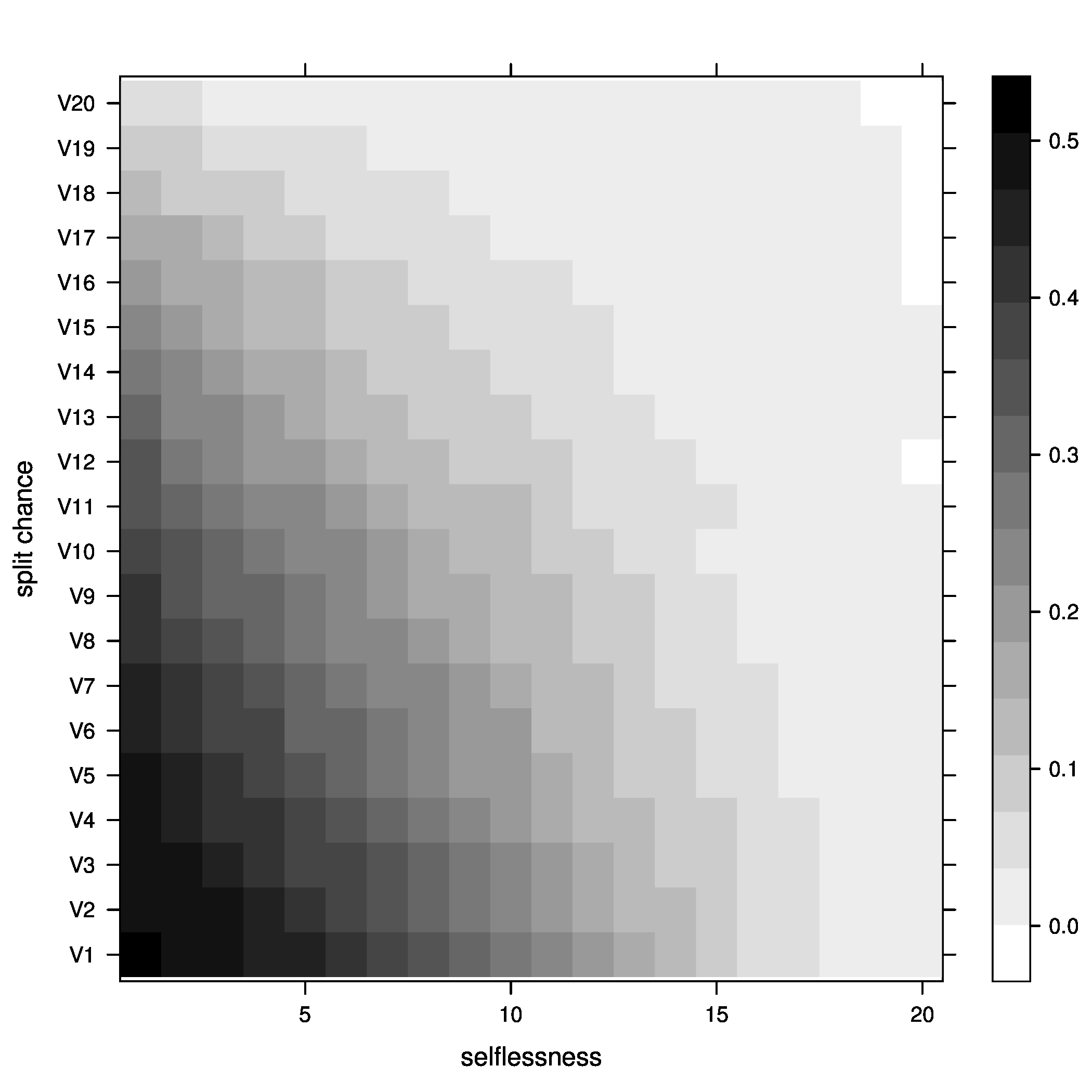
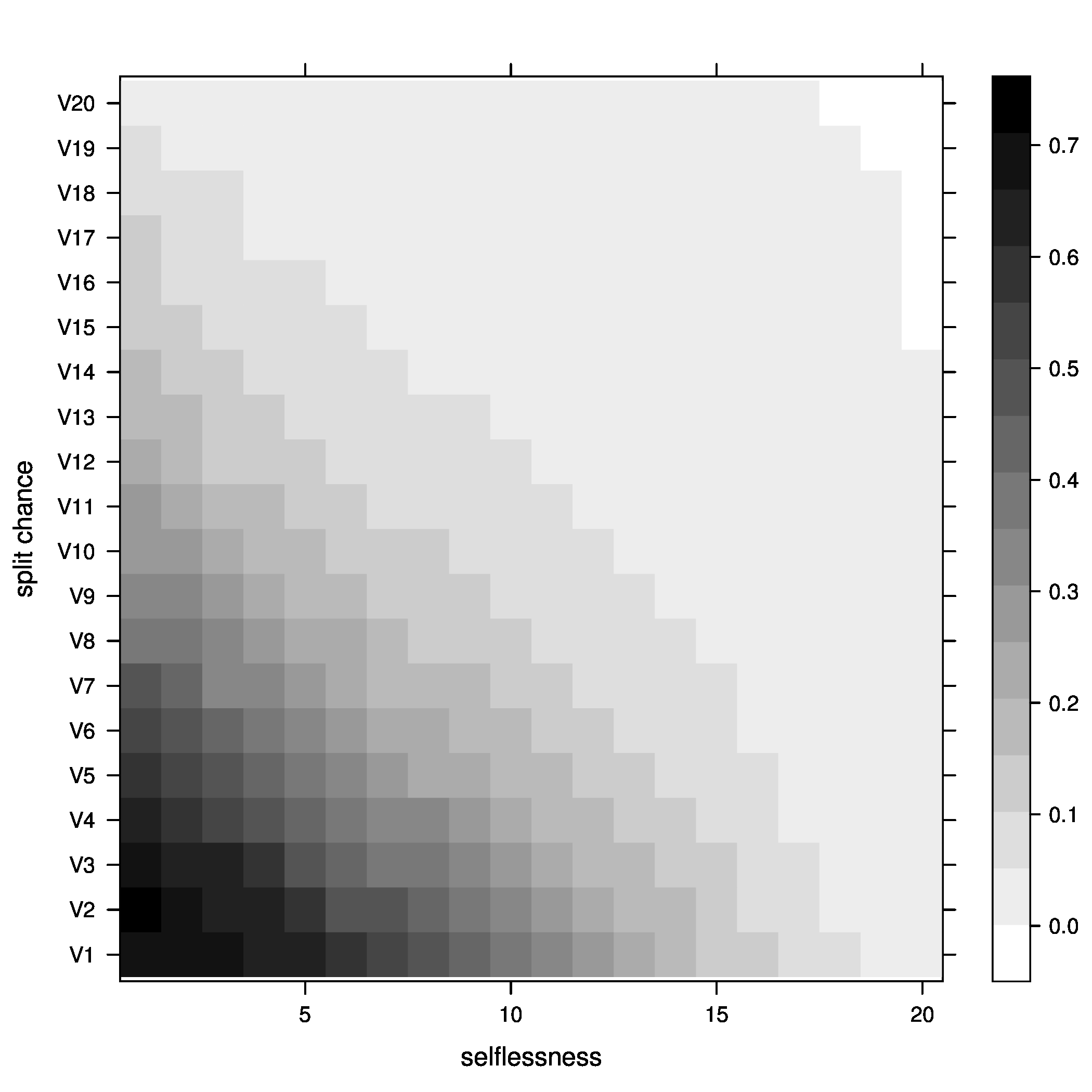
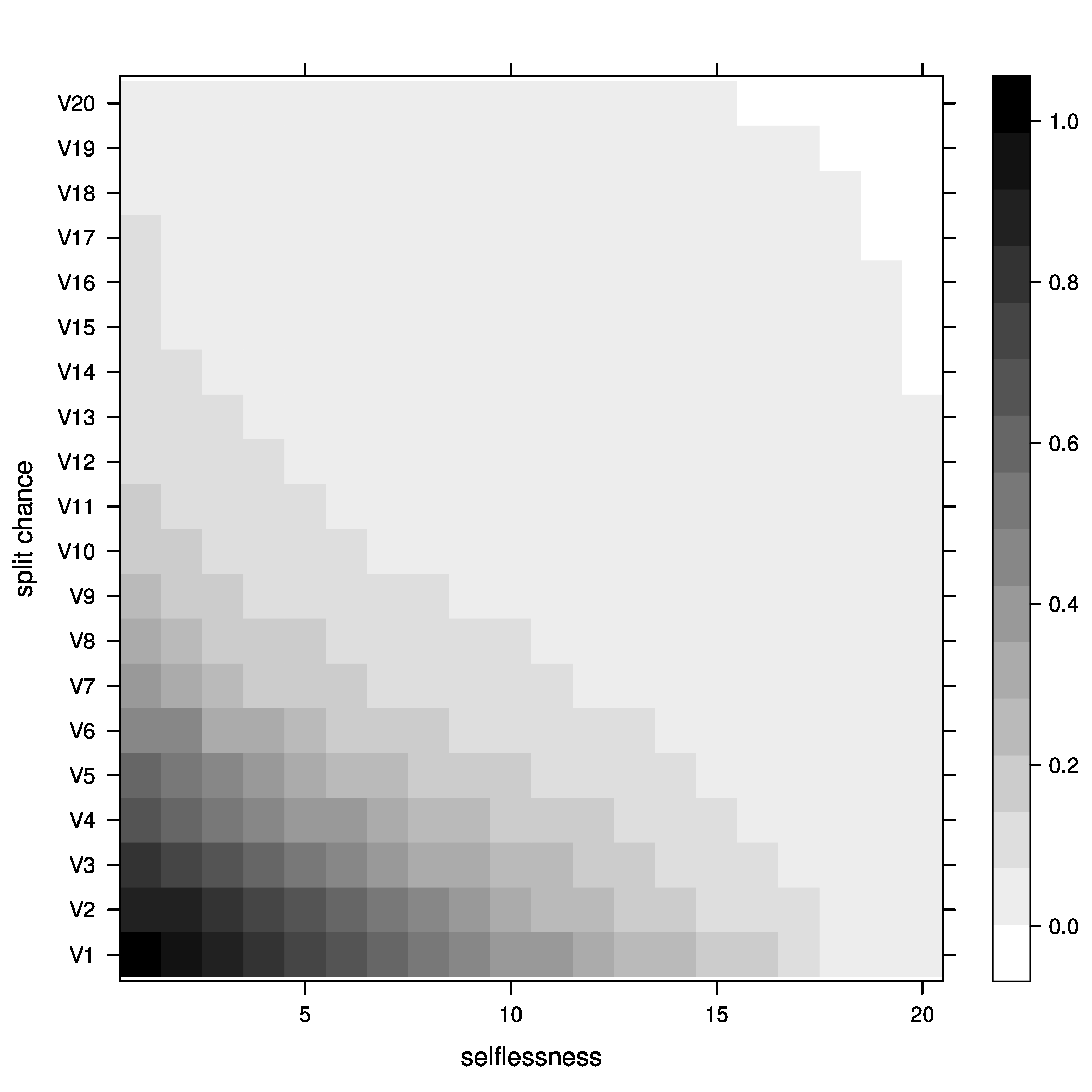
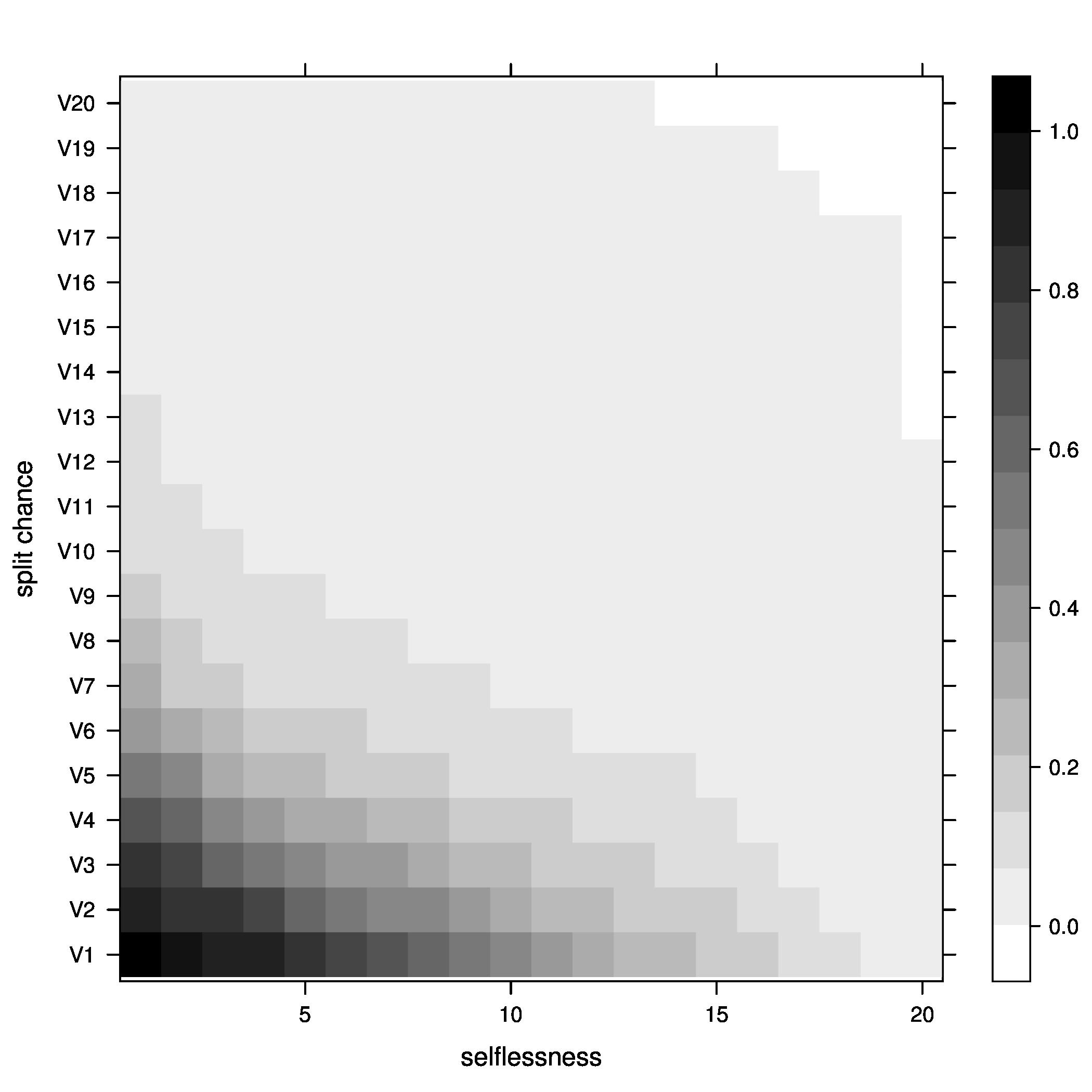
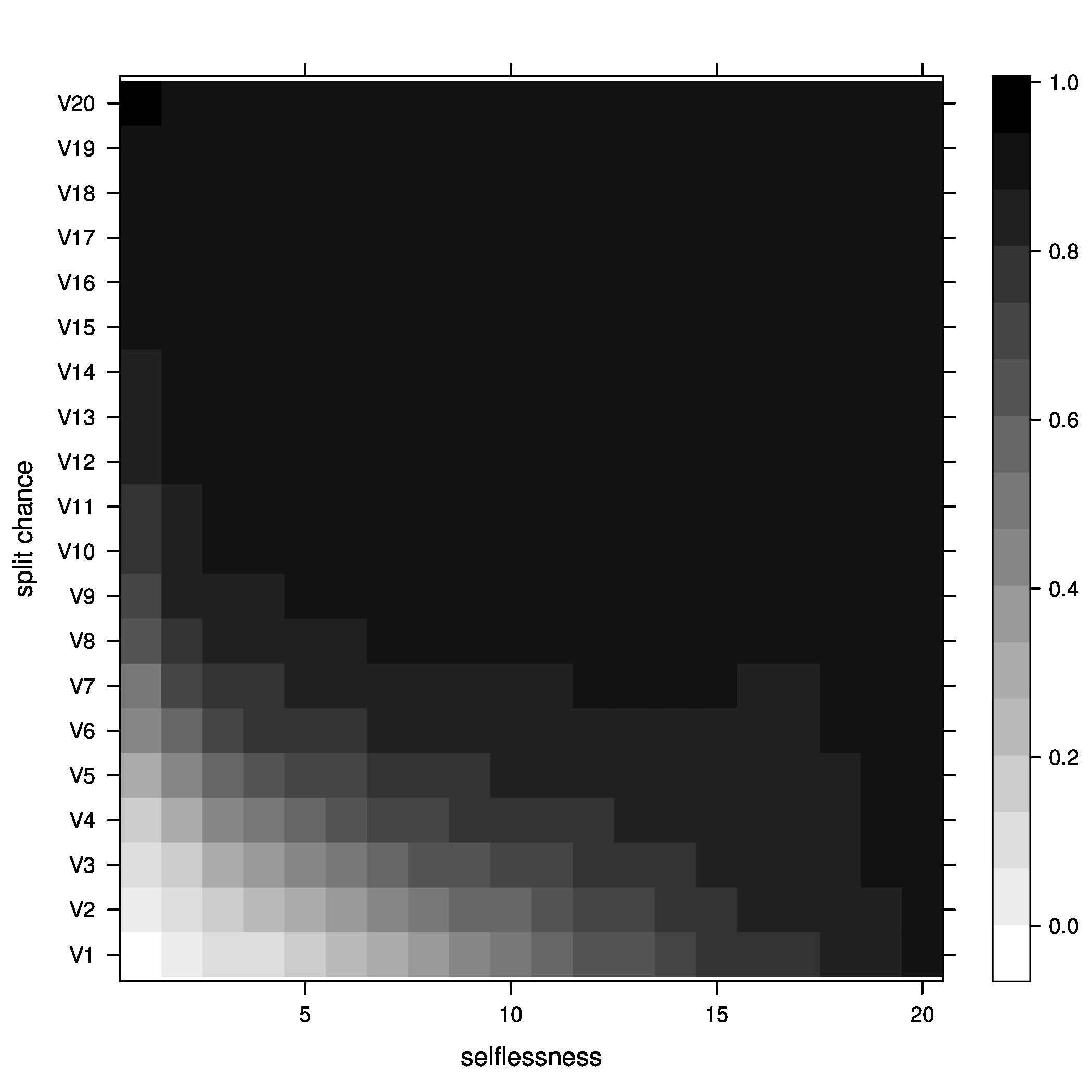
Figure 3: joiners=5, above optimal - Percentage of groups below optimal size
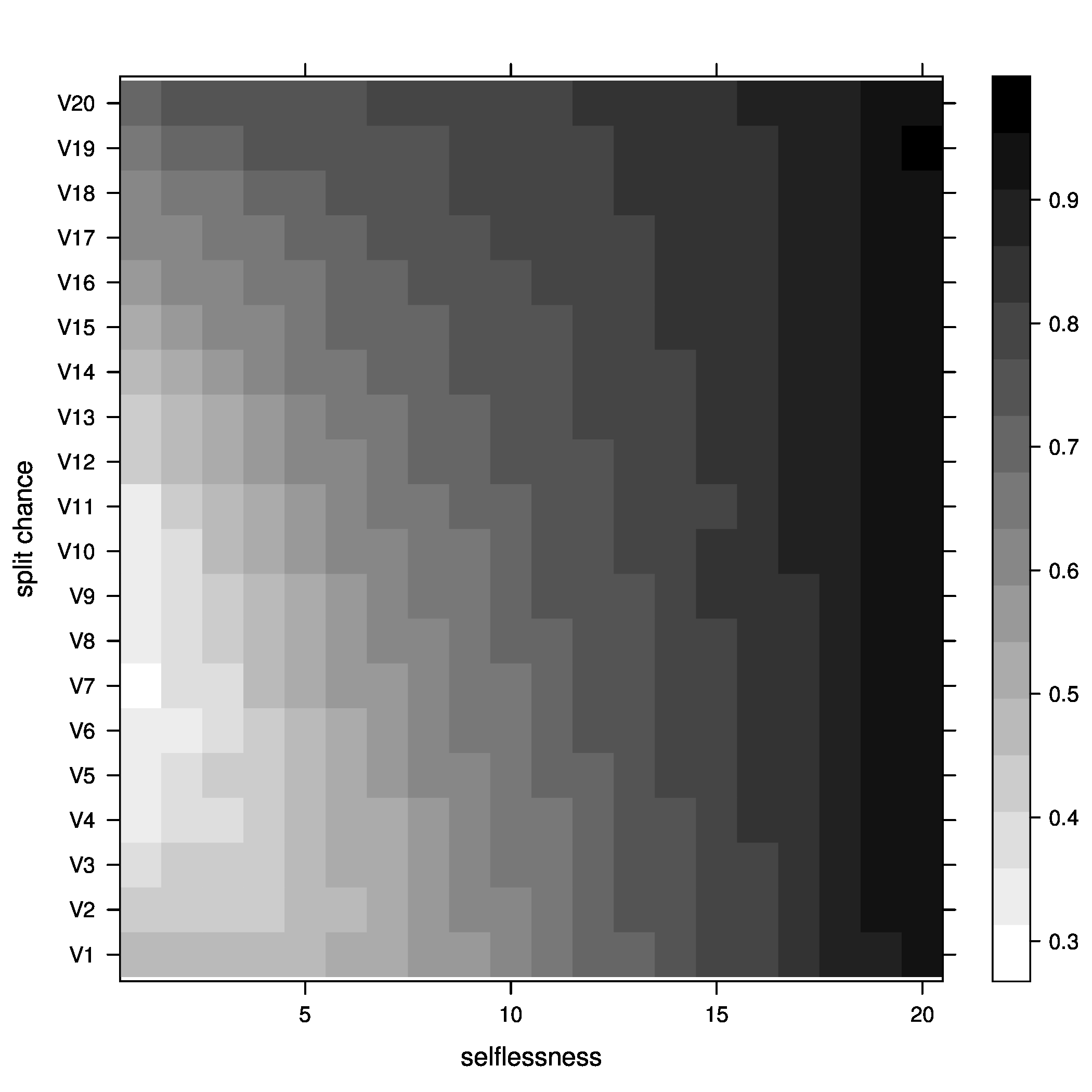
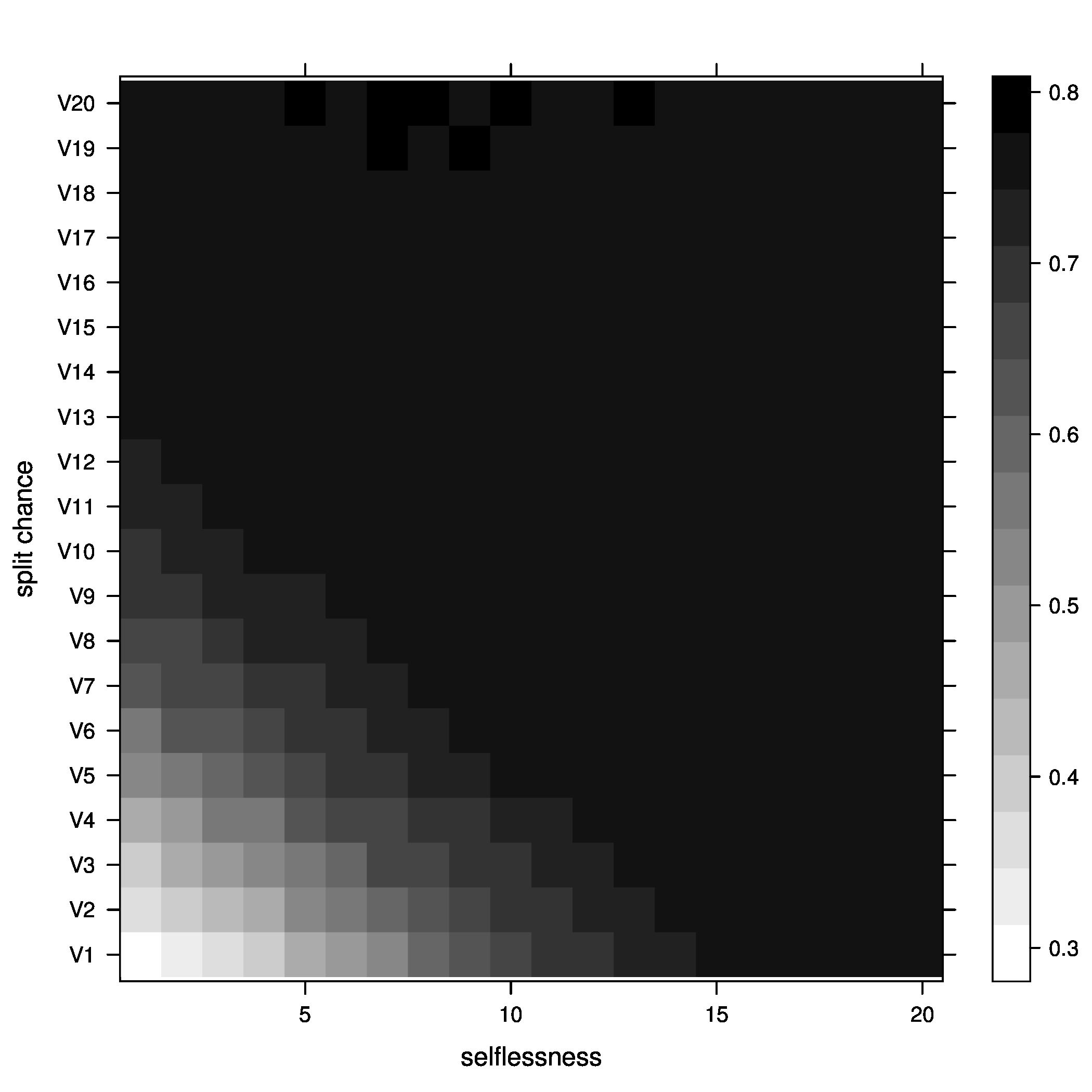
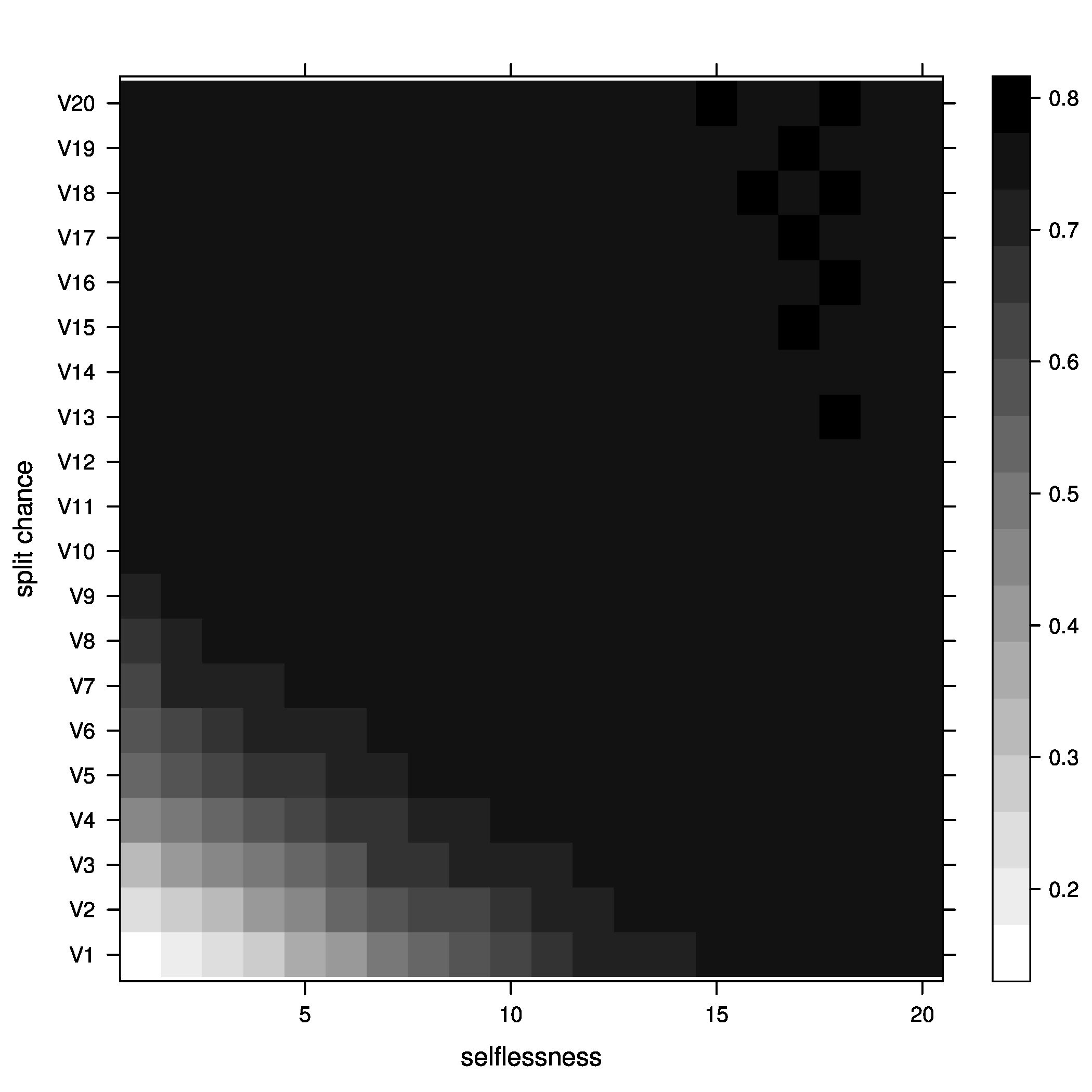
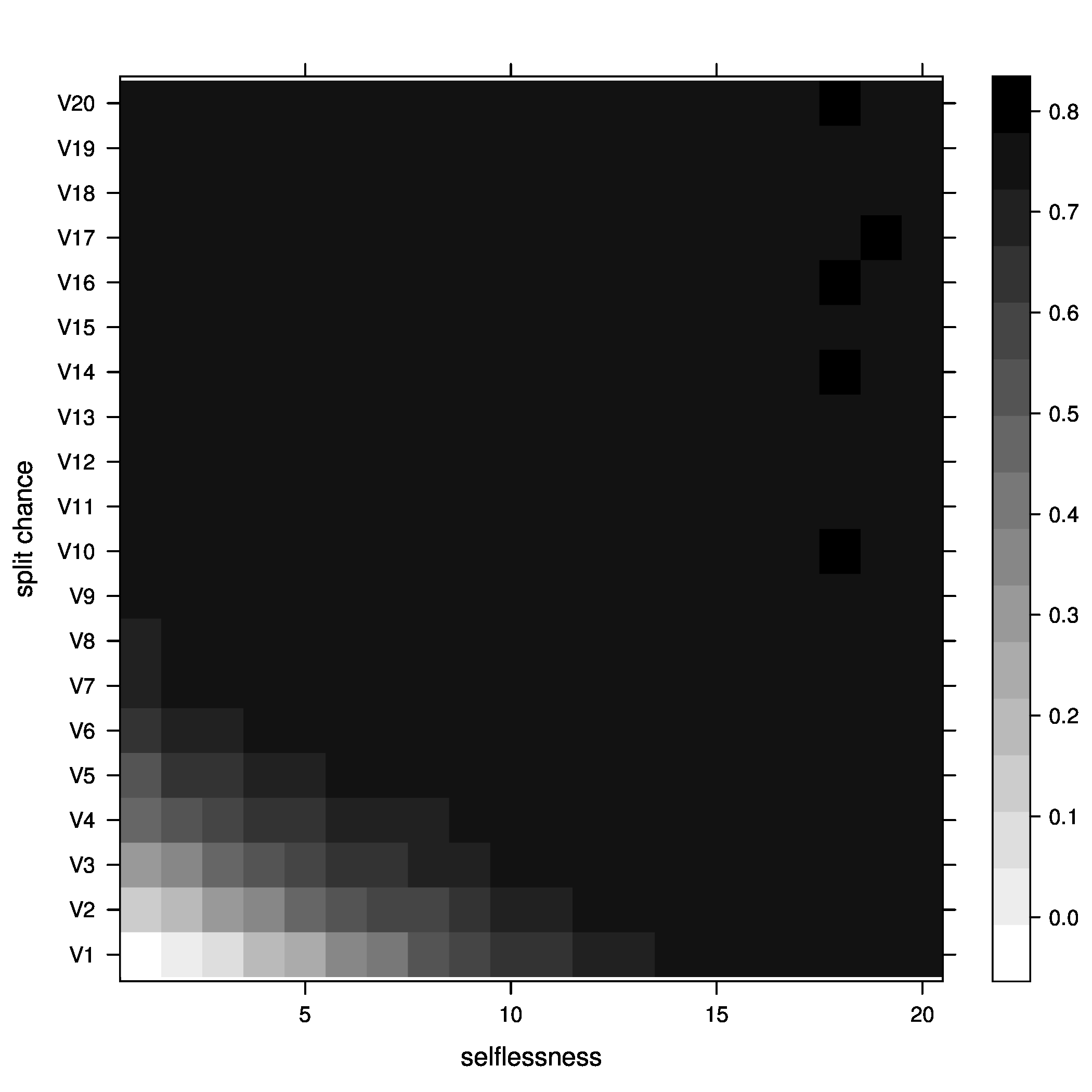
Figure 4: joiners=5, below optimal - Average fitness of groups
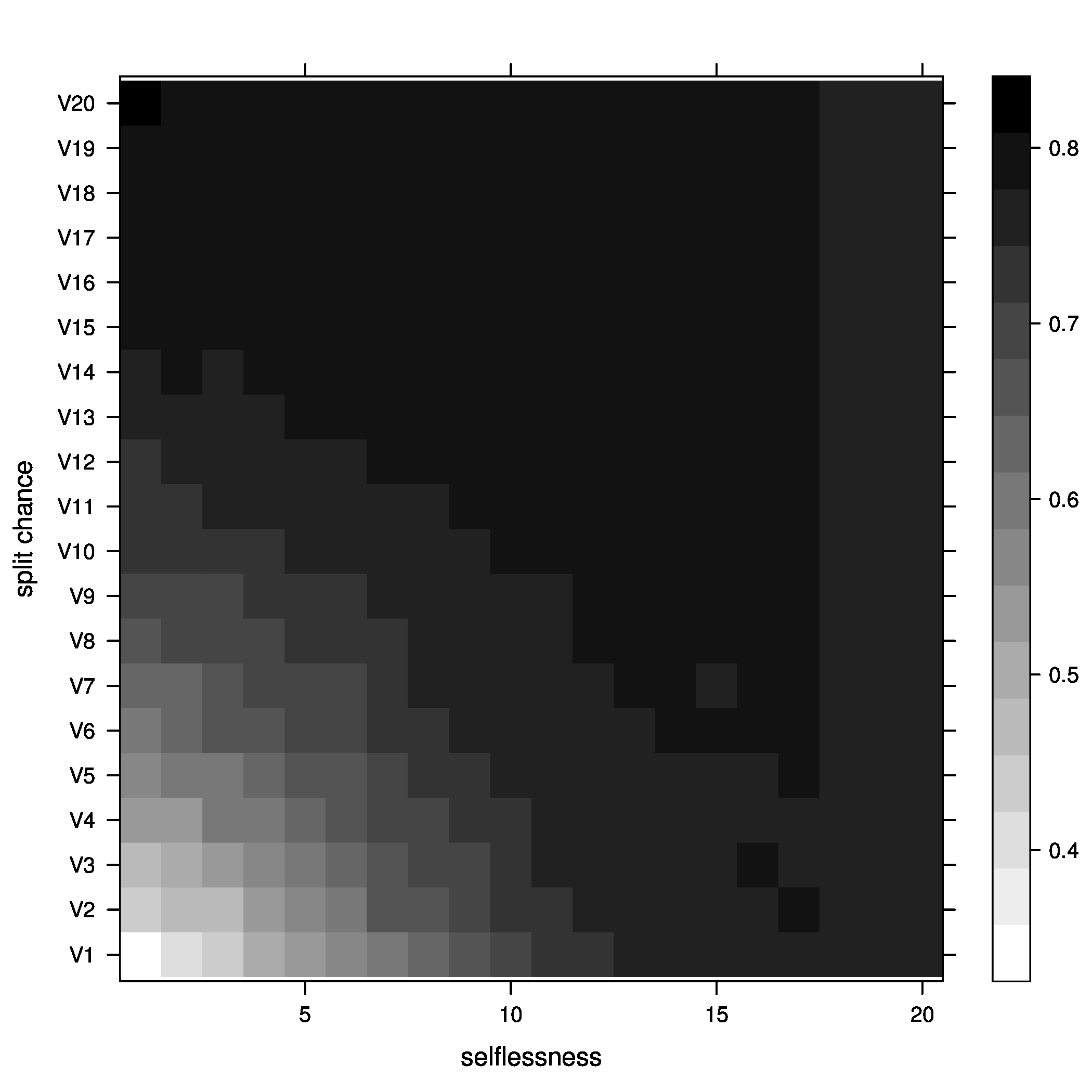
Figure 5: joiners=5, average fitness So, what did we learn here? Well, it looks like the best way to increase chances of getting groups to their optimal size is having a moderate percentage of groups splitting, with no selflessness. We can also see that we get the fewest groups below optimal size at this point (not many really small groups), but we still end up with a decent percentage above optimal size.
One possible explanation for this seemingly unintuitive result could lie in my group splitting logic. When groups split, they split down to optimal size, then the other members get a chance to go join other groups. These members are likely to join small groups, close to their optimal size, bringing the number of small groups down. We can end up with a decent number of groups above optimal size because splitting doesn't happen all that often (the split percent in the region we are investigating is only 30%).
We can also kind of see the same thing happen with selflessness around 65-70 percent, but the effect is nowhere near as pronounced.
The other notable fact is that, although the greatest percentage of optimal groups seems to happen with a small chance of groups splitting, this is not where the average group fitness is highest. The greatest rate of chance in average fitness still looks to be occurring as the chance a group splits increases, meaning that the averages fitness of groups improves faster as we increase the chance of a group splitting than it improves as we increase the chance of selflessness.
Also, something strange seems to be happening with the average fitness graph. I can't really explain that or form much of a conclusion about it. Nothing else grabbed my attention.
I ran only a few more tests, here are the parameters and links to my results.
member_contrib=1.000000 member_detriment=0.500000 num_joiners=10 max_groups=50 trials=1000
at optimal above optimal below optimal average fitness
member_contrib=1.000000 member_detriment=0.500000 num_joiners=15 max_groups=50 trials=1000
at optimal above optimal below optimal average fitness
member_contrib=1.000000 member_detriment=0.500000 num_joiners=20 max_groups=50 trials=1000
at optimal above optimal below optimal average fitness
As you can see, if you looked at these images, the results are fairly consistent across my tests.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Conclusion
It would seem that selflessness doesn't much help, but group splitting does. If you are shooting to find the optimal group size, have a moderate to low percent chance of splitting, and if you want to maximize the average fitness of all the study groups in you meta-study-group group, have a moderate to high chance of splitting. Either way, splitting groups seems to improve the effectiveness of study groups more so than people choosing not to join them when they think they would hurt the group, which seems somewhat intuitive.
To briefly consider the real world, consider that some people damage the group more than others, or help the group more. I think that this effect doesn't really damage the strength of my conclusion, because I am simply proposing that splitting groups when they seem to be becoming unproductive may be an effective way to increase study group effectiveness. When splitting the groups in real life, it is probably a good idea to consider who's who, and of course, if a major productivity killer person decides to not join a group, that will help the group out quite a bit more than choosing to split later.
Hopefully this was interesting to you! If you've seen anything I haven't please tell me!!
A bit about implementation
I wrote this code a couple of different ways, but eventually settled on Haskell as the language for the simulation. I also chose to leave randomness in the simulation, instead of finding all possible outcomes for some given set of parameters and computing percentages from that (the number of cases seems quite large, although performance of what I came up with isn't phenomenal). I also wrote a python script to run multiple instances of the simulation (which is single threaded), and collect the results. The, finally, I used R to spit out the rather unpolished graphics I used.
The code is on github, here is a link to the commit used to write this post.